Machine Learning for People Who Don't Care About Machine Learning
April 10, 2018 • 6 minute read
What is Machine Learning?
The definition I have come up with for Machine Learning is as follows…
machine learning is using data to detect patterns
It involves 2 key concepts:
- Using statistics and math optimize this process
- The optimization process is referred to as training

Here’s the big kicker that will likely make some people unhappy.
It is the same thing as AI.
That’s right I said it. ML and AI are the same thing. I will qualify that this oversimplifies things just a little bit (but only a little bit). When marketing folk talk about AI there is typically the connotation that AI will eventually rule the humans. I have no problem with this. It’s really a way to articulate machine learning that has gotten so good that it can self-learn and adapt to virtually any data you feed it.
This, plus the fact that AI typically has post-apocolyptic undertones.

Nothing is new
What I find really interesting about ML is that none of the concepts are particularly new. The algorithms that are currently en vogue have been around for a while. The major change is that computers have become
- faster
- cheaper
- more readily available
These 3 things, combined with the ever expanding and easy to use machine learning libraries such as scikit-learn, tensorflow (I said the T-word!), and R (I know R isn’t a library) have made machine learning accessible to more people. Accessibility has bred limited real-world usage which in turn has bred hype.
How machine learning works
Machine learning uses different algorithms to detect patterns. These algorithms all do the same thing: they take input data and use it to produce weights. These weights can then be used to make predictions about future observations of data in the same format.
One of the big advances in the past few years is that we (the humans) have come up with ways to relax the strict conditions by which these algorithms are able to accept input. Despite this, almost all algorithms still need to be fed clean, consistent tablular data in order to be effective.
Now when these algorithms train or calibrate, what they’re really doing is finding the minimum distance between a set of points. This is much easier illustrated than typed.
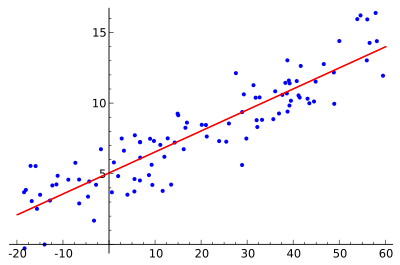
Take the image above as an example. This is a classic simple linear regression. The blue points are the data we want to predict. The red line is the “line of best fit” that our machine learning algorithm (in this case linear regression) has calculated as the best way to characterize this dataset.
You can then use that line to make predictions about future observations.
Classification and Regression
I know what you’re thinking, this is the part where I talk about Tensorflow and how it will fulfill your wildest hopes and dreams while instantly making your business profitable. You are mistaken.
The overwhelming majority of machine learning tasks break down into 2 categories:
- regression – predicting a value (such as price or time to failure)
- classification – predicting the category of something (dog/cat, good/bad, wolf/cow)
In regression, you’re trying to calculate a line that will be “in the middle” of all of your data points (as seen above). In classification, you’re trying ot calculate a line that will “seperate the categories” of your data points.
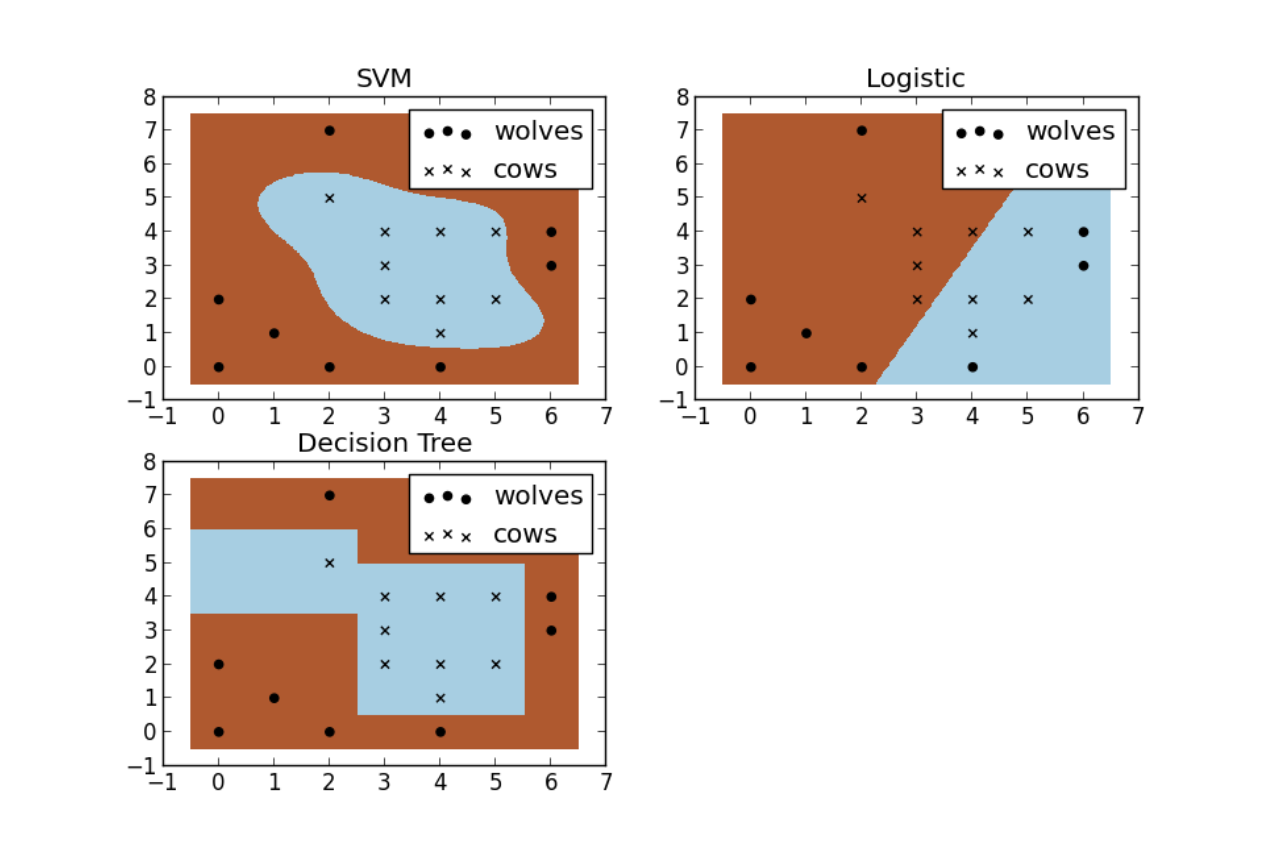
Algorithms
Now here’s the cool part. Different algorithms can use different shapes, numbers, and types of lines to calculate the middle line or seperating line. For instance, in the wolf and cow example above, there are 3 different algorithms beings used to seperate each category. As you can see, the SVM method is non-linear, meaning it doesn’t have to use straight lines. While the logistic method, which is linear, can only seperate points by using a straight line. And then behind door #3 is a decision tree which uses a set auto-generated rules in order to seperate the categories.
So why wouldn’t you always just use the most sophisticated method?
Overfitting
You’re sure this time. I’m going tell you about Tensorflow now. Wrong again!
Well sometimes your model can be too clever. I know these seems like a step backwards but it’s true. Your AI can be too good at understanding the dataset you’re showing it. As a result it’s not general enough to make predictions on future observations.
An analogy is in order. The analogous in a field like Product Management would be if you talked to 1 customer and they said that they wouldn’t buy your product unless the buttons were teal green. The same lovely shade of teal that their company uses in their logo and branding.

If you were a bad product manager then you would listen to that customer and make all of your website’s buttons teal. This is overfitting.
But you’re not a bad product manager. You know that while this one customer might not buy your product because you don’t have teal buttons, you know that there are plenty of other customers out there who aren’t quite as opinionated about button color. This is because you have a solid mental model about what your typical customer really care about.
Greg, are you ever going to talk about Tensorflow?
Fine, we can talk about Tensorflow. Tensorflow is a machine learning library produced by Google. It isn’t all
that easy to use. You need to know what you’re doing in order for it to have a substantially higher ROI than using
one of the simpler, more straightforward libraries such as scikit-learn.

What Tensorflow does really well is provide a modestly intuitive way to define and train neural networks. Neural networks are yet another algorithm you can use to calculate your line. Neural networks, and their cousin deep nerual networks, are handy because they can handle data that is psuedo-unstructured (like images, videos, etc.). I say pseudo-unstructured because ultimate it’s still being fed into the algorithm in a tablular format. You just don’t really have to pay as close attention to how refined and clean that data is. Pretty handy!
Why ML is so hot
It isn’t difficult to do machine learning anymore. I mentioned the wealth of libraries out there. If you can’t tell, I really like `scikit-learn. There are may reasons for this:
- I don’t have to write much code when I use it
- It implements the greatest hits (and then some) of ML. So I can do just about everything without leaving the scikit-learn ecosystem.
- It’s old. In this case, old means mature. Mature means not dealing with mind-numbing bugs.
- The creators and maintainers are very nice and have built up excellent documentation.
- If I have to listen to a lecture about ML, I prefer it come from someone like Olivier Grisel who does everything with just a slight, French accent 🇫🇷, thereby increasing the entertainment value.

My machine learing Francophile fetish aside, scikit-learn reduces building a very sophisticated machine learning model down to 5 lines of code. This is not much code. You don’t need a PhD in astrophysics or even a technical degree to use it:
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()
target_variable = 'does-make-more-than-50k'
columns = ['age', 'education', 'hours-worked-per-week']
clf.fit(df[columns], df[target_variable])